Lost in Translation between R and Python 6
Hello random forest friends
This is the next article in our series “Lost in Translation between R and Python”. The aim of this series is to provide high-quality R and Python 3 code to achieve some non-trivial tasks. If you are to learn R, check out the R tab below. Similarly, if you are to learn Python, the Python tab will be your friend.
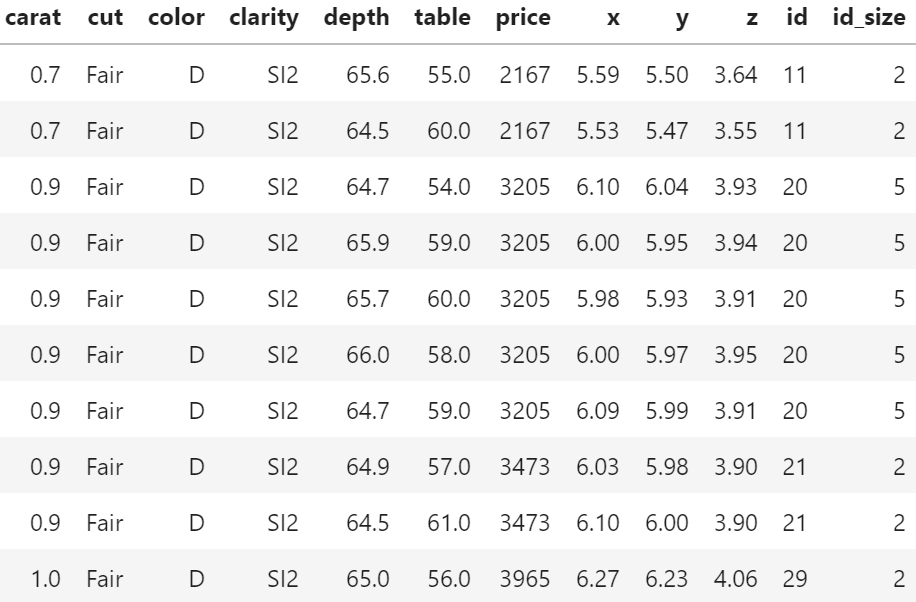
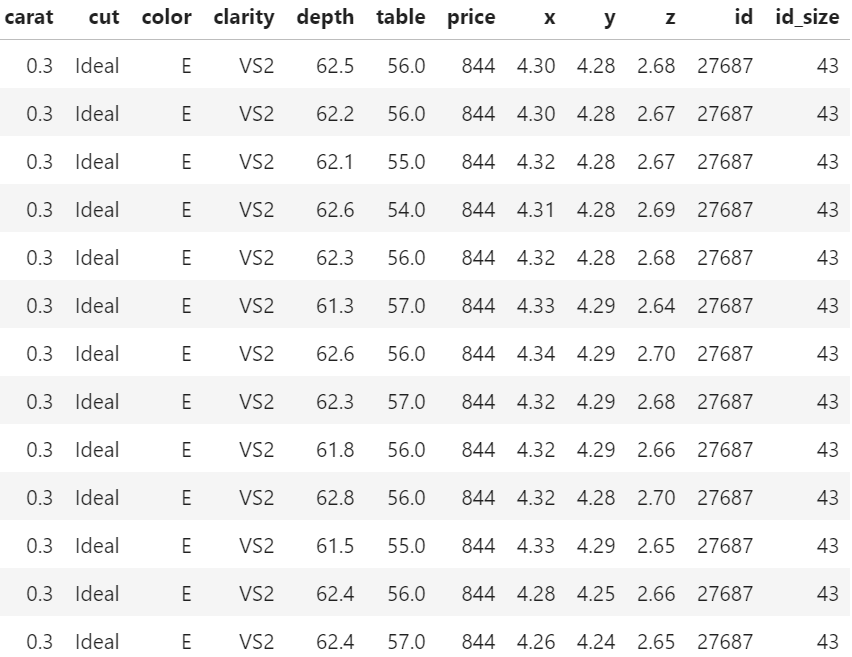
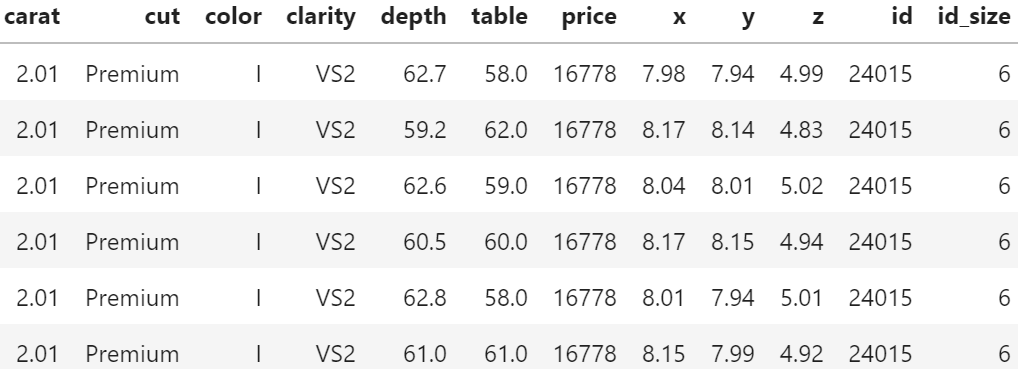
The last one was on diamond duplicates and grouped sampling.
XGBoost’s random forests
For sure, XGBoost is well known for its excellent gradient boosting trees implementation. Although less obvious, it is no secret that it also offers a way to fit single trees in parallel, emulating random forests, see the great explanations on the official XGBoost page. Still, there seems to exist quite some confusion on how to choose certain parameters in order to get good results. It is the aim of this post to clarify this.
Also LightGBM offers a random forest mode. We will investigate it in a later post.
Why would you want to use XGBoost to fit a random forest?
- Interaction & monotonic constraints are available for XGBoost, but typically not for random forest implementations. A separate post will follow to illustrate this in the random forest setting.
- XGBoost can natively deal with missing values in an elegant way, unlike many random forest algorithms.
- You can stick to the same data preparation pipeline.
I had additional reasons in mind, e.g. using non-standard loss functions, but this did not turn out to work well. This is possibly due to the fact that XGBoost uses a quadratic approximation to the loss, which is exact only for the mean squared error loss (MSE).
How to enable the ominous random forest mode?
Following the official explanations, we would need to set
num_parallel_treeto the number of trees in the forest,learning_rateandnum_boost_roundto 1.
There are further valuable tips, e.g. to set row and column subsampling to values below one to resemble true random forests.
Still, most of the regularization parameters of XGBoost tend to favour simple trees, while the idea of a random forest is to aggregate deep, overfitted trees. These regularization parameters have to be changed as well in order to get good results.
So voila my suggestions.
Suggestions for parameters
learning_rate=1(see above)num_boost_round=1(see above)
Has to be set intrain(), not in the parameter list. It is callednroundsin R.subsample=0.63
A random forest draws a bootstrap sample to fit each tree. This means about 0.63 of the rows will enter one or multiple times into the model, leaving 37% out. While XGBoost does not offer such sampling with replacement, we can still introduce the necessary randomness in the dataset used to fit a tree by skipping 37% of the rows per tree.colsample_bynode=floor(sqrt(m))/m
Column subsampling per split is the main source of randomness in a random forest. A good default is usually to sample the square root of the number of features m or m/3. XGBoost offers differentcolsample_by*parameters, but it is important to sample per split resp. per node, not by tree. Otherwise, it might happen that important features are missing in a tree altogether, leading to overall bad predictions.num_parallel_tree
The number of trees. Native implementations of random forests usually use a default value between 100 and 500. The more, the better—but slower.reg_lambda=0
XGBoost uses a default L2 penalty of 1! This will typically lead to shallow trees, colliding with the idea of a random forest to have deep, wiggly trees. In my experience, leaving this parameter at its default will lead to extremely bad XGBoost random forest fits.
Set it to zero or a value close to zero.max_depth=20
Random forests usually train very deep trees, while XGBoost’s default is 6. A value of 20 corresponds to the default in the h2o random forest, so let’s go for their choice.min_child_weight=2
The default of XGBoost is 1, which tends to be slightly too greedy in random forest mode. For binary classification, you would need to set it to a value close or equal to 0.
Of course these parameters can be tuned by cross-validation, but one of the reasons to love random forests is their good performance even with default parameters.
Compared to optimized random forests, XGBoost’s random forest mode is quite slow. At the cost of performance, choose
- lower
max_depth, - higher
min_child_weight, and/or - smaller
num_parallel_tree.
Let’s try it out with regression
We will use a nice house price dataset, consisting of information on over 20,000 sold houses in Kings County. Along with the sale price, different features describe the size and location of the properties. The dataset is available on OpenML.org with ID 42092.
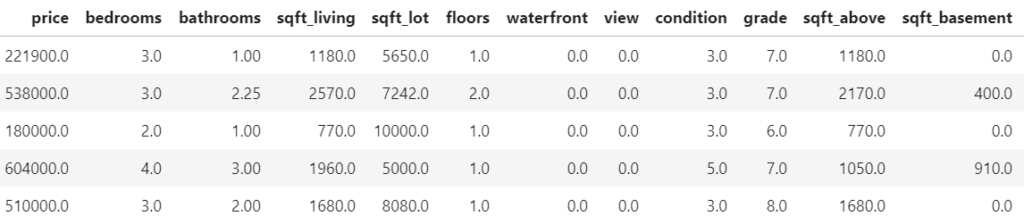
The following R resp. Python codes fetch the data, prepare the ML setting and fit a native random forest with good defaults. In R, we use the ranger package, in Python the implementation of scikit-learn.
The response variable is the logarithmic sales price. A healthy set of 13 variables are used as features.
library(farff)
library(OpenML)
library(dplyr)
library(ranger)
library(xgboost)
set.seed(83454)
rmse <- function(y, pred) {
sqrt(mean((y-pred)^2))
}
# Load King Country house prices dataset on OpenML
# ID 42092, https://www.openml.org/d/42092
df <- getOMLDataSet(data.id = 42092)$data
head(df)
# Prepare
df <- df %>%
mutate(
log_price = log(price),
year = as.numeric(substr(date, 1, 4)),
building_age = year - yr_built,
zipcode = as.integer(as.character(zipcode))
)
# Define response and features
y <- "log_price"
x <- c("grade", "year", "building_age", "sqft_living",
"sqft_lot", "bedrooms", "bathrooms", "floors", "zipcode",
"lat", "long", "condition", "waterfront")
m <- length(x)
# random split
ix <- sample(nrow(df), 0.8 * nrow(df))
# Fit untuned random forest
system.time( # 3 s
fit_rf <- ranger(reformulate(x, y), data = df[ix, ])
)
y_test <- df[-ix, y]
# Test RMSE: 0.173
rmse(y_test, predict(fit_rf, df[-ix, ])$pred)
# object.size(fit_rf) # 180 MB# Imports
import numpy as np
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
def rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true, y_pred))
# Fetch data from OpenML
df = fetch_openml(data_id=42092, as_frame=True)["frame"]
print("Shape: ", df.shape)
df.head()
# Prepare data
df = df.assign(
year = lambda x: x.date.str[0:4].astype(int),
zipcode = lambda x: x.zipcode.astype(int)
).assign(
building_age = lambda x: x.year - x.yr_built,
)
# Feature list
xvars = [
"grade", "year", "building_age", "sqft_living",
"sqft_lot", "bedrooms", "bathrooms", "floors",
"zipcode", "lat", "long", "condition", "waterfront"
]
# Data split
y_train, y_test, X_train, X_test = train_test_split(
np.log(df["price"]), df[xvars],
train_size=0.8, random_state=766
)
# Fit scikit-learn rf
rf = RandomForestRegressor(
n_estimators=500,
max_features="sqrt",
max_depth=20,
n_jobs=-1,
random_state=104
)
rf.fit(X_train, y_train) # Wall time 3 s
# Test RMSE: 0.176
print(f"RMSE: {rmse(y_test, rf.predict(X_test)):.03f}")Both in R and Python, the test RMSE is between 0.17 and 0.18, i.e. about 2/3 of the test predictions are within 18% of the observed value. Not bad!
Note: The test performance depends on the split seed, so it does not make sense to directly compare the R and Python performance.
With XGBoost’s random forest mode
Now let’s try to reach the same performance with XGBoost’s random forest implementation using the above parameter suggestions.
# Fit untuned, but good(!) XGBoost random forest
dtrain <- xgb.DMatrix(data.matrix(df[ix, x]),
label = df[ix, y])
params <- list(
objective = "reg:squarederror",
learning_rate = 1,
num_parallel_tree = 500,
subsample = 0.63,
colsample_bynode = floor(sqrt(m)) / m,
reg_lambda = 0,
max_depth = 20,
min_child_weight = 2
)
system.time( # 20 s
fit_xgb <- xgb.train(
params,
data = dtrain,
nrounds = 1,
verbose = 0
)
)
pred <- predict(fit_xgb, data.matrix(df[-ix, x]))
# Test RMSE: 0.174
rmse(y_test, pred)
# xgb.save(fit_xgb, "xgb.model") # 140 MBimport xgboost as xgb
dtrain = xgb.DMatrix(X_train, label=y_train)
m = len(xvars)
params = dict(
objective="reg:squarederror",
learning_rate=1,
num_parallel_tree=500,
subsample=0.63,
colsample_bynode=int(np.sqrt(m))/m,
reg_lambda=0,
max_depth=20,
min_child_weight=2
)
rf_xgb = xgb.train( # Wall time 34 s
params,
dtrain,
num_boost_round=1
)
preds = rf_xgb.predict(xgb.DMatrix(X_test))
# 0.177
print(f"RMSE: {rmse(y_test, preds):.03f}")We see:
- The performance of the XGBoost random forest is essentially as good as the native random forest implementations. And all this without any parameter tuning!
- XGBoost is much slower than the optimized random forest implementations. If this is a problem, e.g. reduce the tree depth. In this example, Python takes almost twice as much time as R. No idea why!
The timings were made on a usual 4 core i7 processor. - Disk space required to store the model objects is comparable between XGBoost and native random forest implementations.
What if you would run the same model with XGBoost defaults?
- With default
reg_lambda=1:
The performance would end up at a catastrophic RMSE of 0.35! - With default
max_depth=6:
The RMSE would be much worse (0.23) as well. - With
colsample_bytreeinstead ofcolsample_bynode:
The RMSE would deteriorate to 0.27.
Thus: It is essential to set some values to a good “random forest” default!
Does it always work that good?
Definitively not in classification settings. However, in regression settings with the MSE loss, XGBoost’s random forest mode is often as accurate as native implementations.
- Classification models
In my experience, the XGBoost random forest mode does not work as good as a native random forest for classification, possibly due to the fact that it uses only an approximation to the loss function. - Other regression examples
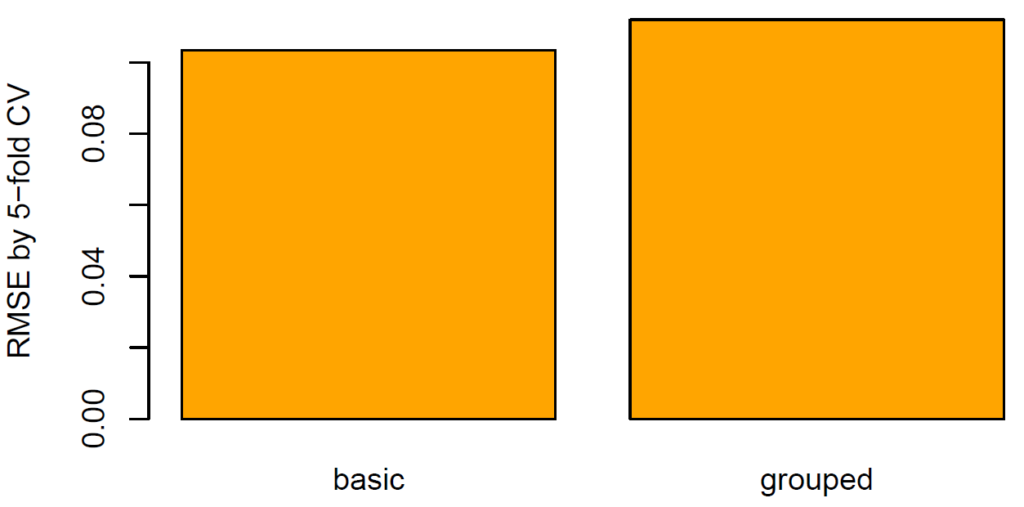
Using the setting of our last “R <–> Python” post (diamond duplicates and grouped sampling) and the same parameters as above, we get the following test RMSEs: Withranger(R code in link below): 0.1043, with XGBoost: 0.1042. Sweet!
Wrap up
- With the right default parameters, XGBoost’s random forest mode reaches similar performance on regression problems than native random forest packages. Without any tuning!
- For losses other than MSE, it does not work so well.
The Python notebook and R code can be found at: